
News

Any workload running on AWS has a release strategy. It might be a less-than-perfect release strategy involving many manual steps and including areas where problems can be introduced, but it’s a strategy nonetheless. This article aims to help you appreciate the importance of a good release strategy that ensures changes are controlled and reversible in the event of failure.
We’ll dive into the methods that make up a good release strategy and the AWS tools that can help us implement them. Throughout, we’ll reinforce the idea of release velocity and quality being a function of CI/CD capability – the theory that with greater automation and control comes an increase in high-quality throughput.
Releasing changes properly is of utmost importance. The right way for one workload isn’t necessarily the right way for another. For example, a mission-critical workload where any downtime is considered a major problem would have different requirements to a rarely used internal tool where periods of downtime are unlikely to be noticed.
It’d be amiss to talk about releasing changes on AWS the right way without talking about infrastructure-as-code (IaC) tools like AWS CloudFormation and Hashicorp Terraform. These tools allow you to define AWS infrastructure in either a procedural or declarative manner, enabling the control and audit of any changes to resources deployed. Whilst we won’t talk about these tools in every subsequent section, know that all strategies should utilise IaC.
CI/CD is likely a term you’ve heard before. The acronym stands for ‘Continuous Integration and Continuous Deployment’. Let’s explore each individually before bringing them back together and looking at some of the tools AWS has to offer.
Continuous Integration (CI) refers to automated pipelines that do everything short of releasing workloads within the software development lifecycle. Some activities may include building artefacts, running tests, performing static analysis, checking code formatting and quality, and notifying developers of success or failure. The key driver behind a CI pipeline embeds the concept of ‘shifting responsibility left’, empowering developers to find out earlier if their proposed change would be successfully integrated into the live system – also known as ‘failing fast’.
Continuous Deployment (CD) is the idea of automatically deploying software or infrastructure configuration when changes are detected in source code. This is typically set up with Git branches as the source, with pipelines triggered when feature branches are merged into them. Infrastructure-as-code is especially important here – having your infrastructure defined in a way that can be compared against actual deployed infrastructure is invaluable when incrementally releasing changes.
For example, consider the following command from the AWS CLI. If this was in a script that ran to set up infrastructure, it could only run once before failing on subsequent attempts due to the bucket already existing.

Let’s compare it to an infrastructure-as-code tool, Terraform. The configuration below defines the desired state of our infrastructure rather than the commands required to create our infrastructure. When Terraform runs for the first time, it will create the bucket. On subsequent runs, it knows that the bucket already exists and doesn’t try to create it again.

CI/CD combines the best of both worlds. With greater confidence in proposed changes via CI pipelines and greater control of enacting changes via CD pipelines, the velocity and quality of releases increase. Any development team in this day and age should be utilising modern DevOps techniques such as CI/CD pipelines.
There are many tools on the market for CI/CD pipelines. AWS has a first-party offering that supports both CI and CD use cases: AWS CodePipeline.
AWS CodePipeline is there to help orchestrate the varying stages in a pipeline, pulling from a source code repository and doing something with it. CodePipeline can pass artefacts between stages by storing outputs in an Amazon S3 bucket. Typical stages a pipeline might run through are Source, Build, Test, and Deploy. CodePipeline also supports manual approval steps, where stakeholders can be notified that a release is ready for human validation before progressing.
AWS CodeBuild is a service that is often paired with CodePipeline as a way to run shell scripts. It runs these scripts inside a container and can be used for a variety of purposes. Ultimately, any commands you need to run for deployments can be implemented in a CodeBuild job and form part of your CI/CD pipeline.
CodePipeline integrates with much more than just CodeBuild. Check out the full list of integrations.
There are several deployment strategies that can be employed, and each has its place. Let’s explore each one in more detail before moving on to the AWS tools that are there to make our lives easier.
In-place deployment refers to releasing a new version of the application on the same infrastructure that’s currently serving the live version. If you’re only running one instance of your application, this will result in downtime, as the existing version has to be stopped, and the new version has to be installed and started.
To avoid downtime, the in-place deployment strategy can be combined with the rolling strategy. We’ll explore this a bit further later.
All-at-once deployment is pretty much what it says on the tin. Consider a horizontally-scaled application running on ECS. This deployment strategy would replace all the ECS tasks in the service at once with the new version of the application. As soon as the new version is released, the old tasks no longer exist.
A major disadvantage of this is that it gives you no opportunity to test a release with production traffic before all production traffic is served by the new release. If a bug was introduced, all users could be affected and experience downtime whilst you re-deploy the old version.
A blue/green strategy involves deploying two variants of the application at once, where only one is live. Blue refers to the live version, and green refers to the idle version. To begin with, the blue variant is the existing release of the application whilst the green variant is the new release sitting idly. After the new variant has been tested, blue and green switch so the new variant is live and the old version is idle. If all goes well, the old version (green) should be tidied up.
An advantage of this over all-at-once is that if bugs are introduced in the new version, it’s easy and quick to redirect all traffic back to the old release. A disadvantage of this strategy is that it’s still not tested with any production traffic before all is switched over.
Canary deployments start to introduce some nice behaviours and resolve the disadvantages we’ve seen so far. With a canary deployment, a new version of the application is deployed and made available to a small subset of users. These users are the ‘canaries’. If no errors are experienced, the deployment proceeds incrementally and slowly. When a pre-determined point is reached, and there is a high degree of confidence that the new version works, all traffic shifts to the new version and the old version is destroyed.
The major advantage is that the new release is gradually exposed to production traffic, and there are plenty of opportunities to switch back to the old version. Switching back to the old version doesn’t sacrifice any capacity, as the two application variants are maintained independently of each other.
A/B testing is slightly different from the others in that it could be combined with each of them. It’s more of a way of testing features and determining impact. This is often also referred to as feature flags.
Suppose your application has a new feature you want to test with only 10% of your users. Rather than deploying a whole new set of infrastructure and shifting 10% of the traffic to it, which wouldn’t guarantee the same users each time, you deploy a new release with logic at the application level to determine what functionality to serve. Certain users could have a flag set in the database that signifies they are within the chosen sample, and then code similar to the snippet below could handle switching functionality.
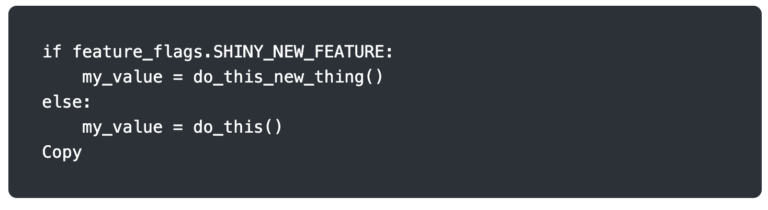
There are significantly more graceful ways to use A/B testing and feature flags, and some very good open-source and commercial offerings are available. The brief example above is provided for easy illustration.
Rolling deployments have similarities to canary deployments in that the new version of the application is exposed gradually to production traffic. The key difference is that rolling deployments proceed through each instance of the application, whereas canary deployments are more staged; the canary strategy reaches a certain point and then switches all over, whereas rolling continues to trundle on at the same pace.
One disadvantage of rolling deployments is that, because it replaces instances of the application as it goes rather than incrementally shifting traffic, it can be slower to roll back changes and get back to full capacity. In comparison, canary deployments maintain two versions and shift traffic between them, removing the old version when the overall deployment is successful.
Various tools within AWS are available depending on how a workload is deployed. Let’s explore in more detail three ways in which AWS can help.
Serverless – my favourite! API Gateway supports two of the deployment strategies we’ve looked at.
When you’re ready to release a new version of an API, a deployment is created. This deployment exists as an immutable representation of the new configuration to be released. An API Gateway stage points to a deployment (or deployments).
With API Gateway, a stage can switch all traffic to the new deployment, implementing a form of the blue/green deployment strategy. Unlike a blue/green deployment using a service like Amazon EC2, where instances are created and terminated, the old deployment in API Gateway doesn’t go anywhere, so it’s very easy to roll back if there are any bugs in the new version, even weeks later.
Alternatively, a stage can be set up as a ‘canary deployment’. As we’ve learned, some traffic is sent to the new deployment and some to the old. When we’re confident that the new release is error-free, all traffic is directed to the new deployment.
AWS CodeDeploy supports releasing to EC2 instances, Lambda functions, or ECS services. The platform you’re releasing to determines which deployment strategies are available to you.
Deploying to EC2 instances supports the in-place deployment strategy and blue/green strategy.
For in-place deployments, the new application can be deployed to the instance/s all at once, one half at a time, or one instance at a time. The fewer instances you deploy to at once, the greater the chance you have to catch errors, but the slower the release is.
For blue/green deployments, CodeDeploy will provision new instances in the green environment. Traffic can be shifted to this environment at once or one half at a time.
Lambda functions do not support in-place deployments. The supported deployment strategy is blue/green, and then traffic can be shifted using three different methods.
When CodeDeploy deploys a new version of a Lambda function, it can shift traffic all at once. If this is too risky, then canary deployments are also supported. For example, CodeDeploy has a predefined configuration for shifting 10% of traffic and then shifting the remaining 90% 10 minutes later. If you need more confidence around your new function version handling increasing amounts of load, linear strategies are possible. For example, shift 10% of the traffic every 2 minutes. Linear is very similar to rolling; however, rolling is typically more applicable when you’ve got a finite number of instances to deploy to—for example, 10 EC2 instances behind a load balancer in an auto-scaling group.
In the context of CodeDeploy, the functionality that is supported when your workload runs as an Amazon ECS service is exactly the same as that for Lambda functions. Everything’s under the umbrella of blue/green here.
CodeDeploy can shift all traffic to the green version at once or follow the canary or linear strategy of introducing traffic to the new application release in multiple stages.
Application Load Balancer (ALB) is a tool that supports implementing deployment strategies rather than a service that will orchestrate the process for you. With CodeDeploy, you can define a strategy (e.g. CodeDeployDefault.ECSLinear10PercentEvery3Minutes), whereas with ALB you would need to implement the logic yourself.
The core ALB functionality that enables different deployment strategies is weighted target groups. This is an extension of the normal target group functionality. To set the scene, target groups are attached to an ALB listener rule and define where requests should be sent when rules are matched. For example, a listener could be set up on port 443 with a rule that dictates it should forward any requests with a path matching the pattern /api/*. A target group containing EC2 instances would be attached to this rule to handle all API requests.
Weighted target groups allow you to specify the percentage of traffic that should be directed to each target group. With this functionality, a number of strategies are possible. Once the new target group has been attached, you could opt to shift 100% in one go. You could follow the canary strategy and shift 10% before shifting the remaining 90% after a set time period, or you could implement a linear traffic shift with 10% of traffic shifting each minute.
The biggest advantage of implementing this all through an ALB is that it’s agnostic to the service it’s routing traffic to. It doesn’t care if you’re running a strange operating system on your EC2 instances that isn’t supported by CodeDeploy. The downside is that you’re responsible for implementing these strategies yourself; there are no predefined helpers, and it’s up to your continuous deployment pipelines to include scripts to shift the traffic while ensuring the new deployment is healthy.
In summary, we’ve explored why it’s important to release changes in the right way, introduced the concept of Continuous Integration and Continuous Deployment, demystified various deployment strategies and surfaced some AWS tools that can help implement these strategies.
Modern DevOps and the use of CI/CD pipelines form a large part of the Operational Excellence pillar within the AWS Well-Architected Framework. If you’ve read this and would like assistance improving the quality and velocity of releasing into AWS, schedule a Well-Architected Framework Review with Ubertas Consulting. We’re here to help.

Alex Kearns
Principal Solutions Architect, Ubertas Consulting

