

News
Anything that can go wrong, will go wrong!

This post focuses on the ‘Anticipate failure’ design principle contained in the Operational Excellence pillar of the Well-Architected Framework.
It will explore Murphy’s law in the context of AWS, discussing a variety of topics ranging all the way from simple auto-healing and scaling of an EC2 instance up to full multi-region disaster recovery. Two scenarios will be posed: an SMB SaaS application and a business-critical enterprise application. Decreasing tolerance to failure comes with different recommendations and strategies.
It’s important to note that not every application needs complex multi-region deployments, but architecting with global resilience in mind is something that most would benefit from. Whilst it may not be needed now, it encourages best practices and removes obstacles to future growth.
Before we dive into the scenarios mentioned, let’s cover a little bit of background to ensure we’re all on the same page.
There’s two types of redundancy to talk about here. One is inter-regional redundancy and the other is intra-regional. Let’s start with intra-regional.
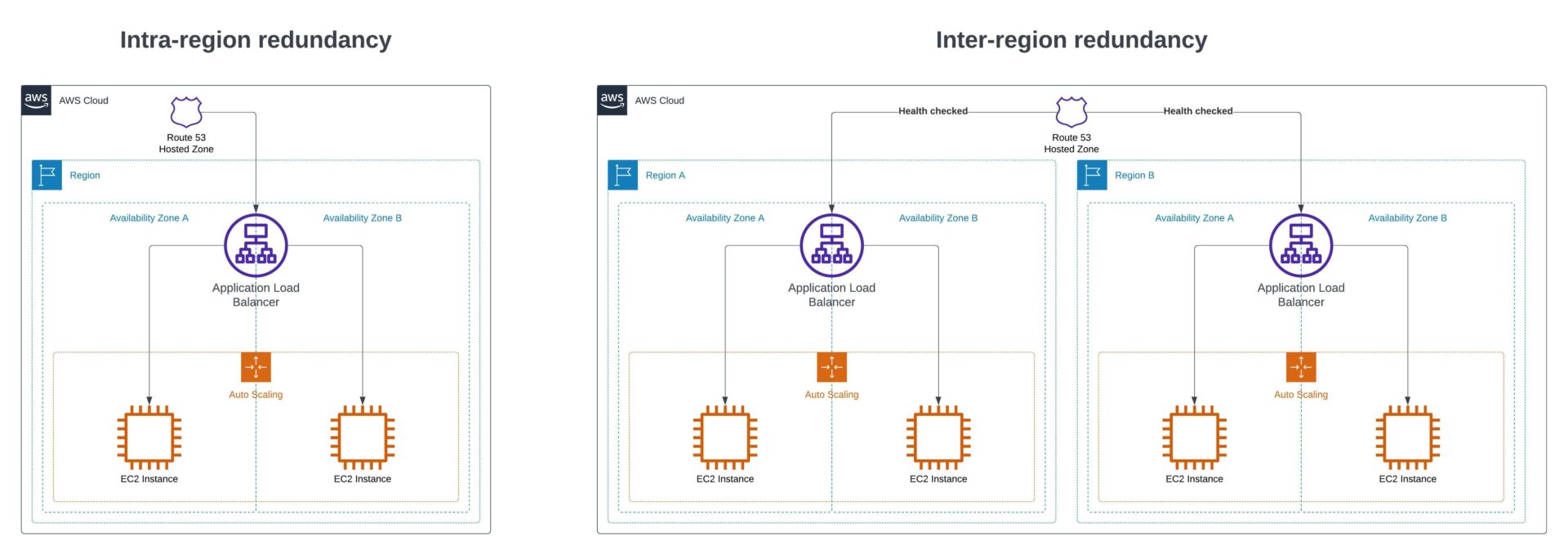
Example architectures using intra-region and inter-region redundancy. Source: Ubertas Consulting.
Intra-regional redundancy refers to an application being only as resilient as a single AWS region. In real terms, this is still significantly more redundant than a single on-premises data centre due to an AWS region being made up of multiple data centres, also known as Availability Zones (AZs). AZs are built so that one or more data centres within a region can fail without taking the whole region out of service. An application can be deployed cross-AZ (i.e. into multiple data centres) to help protect against single points of failure. For most applications built on AWS, it’s recommended to employ this type of redundancy. The chances of an entire region becoming unhealthy are very slim and acceptable to many organisations. Many AWS services will automatically give you redundancy across all AZs in a region. For example, Amazon S3 will store your data across multiple AZs at no additional cost, without you having to specify which AZs to store your objects in.
Inter-regional redundancy means that the application is deployed across multiple regions. Typically, this type of redundancy would be utilised for mission-critical applications where even the remote possibility of an entire AWS region being unhealthy is not acceptable. Deploying across multiple regions brings benefits and opportunities but also brings additional complexities. A handful of AWS services do integrate nicely across multiple regions. Still, there are some things to consider, such as replication lag within the context of database services.
When it comes to increasing the resiliency of an application, there are a number of strategies that can be used in an architecture. All of these strategies can be used both inter- and intra-region; however, typically, disaster recovery (DR) tends towards inter-region (i.e. a different region to the application). We’ll review them in increasing cost and decreasing return to operation (RTO) and recovery point objective (RPO) times.
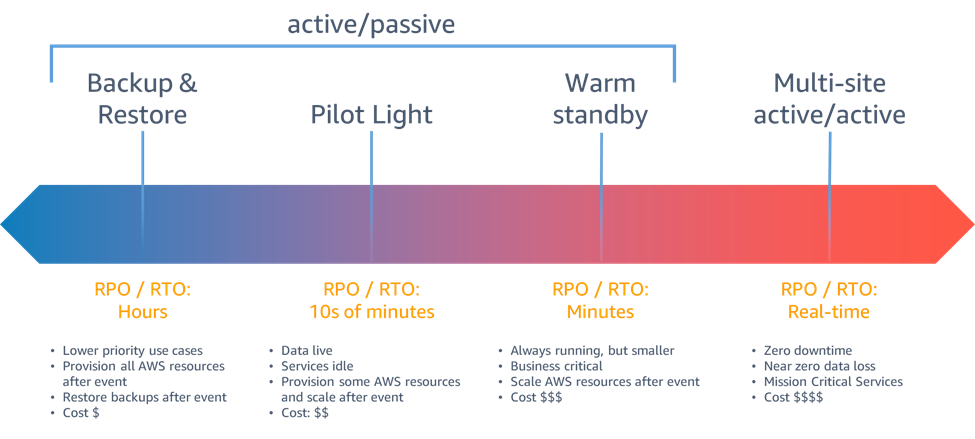
Disaster recovery (DR) strategies. Source: AWS.
This is the closest to your “traditional” DR strategy. Remember the old 3-2-1 backup strategy? Three copies of data, two on different storage types and one on-site. Data is backed up to a location separate from where the application is deployed. In the disaster recovery location, no infrastructure is provisioned or configured, and the disaster recovery process involves setting up the infrastructure and restoring the backups onto the new infrastructure.
The pilot light strategy is a step up from backup and restore, with the key difference being that some infrastructure is configured but not necessarily provisioned. For example, an ECS service could be configured but with no instances of the application running. This reduces the RTO time by removing the need to deploy boilerplate configurations while keeping costs low due to no infrastructure being deployed.
Warm standby builds upon the pilot light strategy in that infrastructure is configured, but in this case, it’s also provisioned to a minimal extent. What this means is that if the production specification of an application is 4 tasks running in an ECS service, the warm standby might have 1 task running. This strategy is the first that could functionally serve any traffic, just not at the scale of production.
This is the most expensive strategy, but comes with the shortest RTO and RPO timeframes. Unlike strategies like backup and restore, data replication is near-real time. Taking warm standby to the next level, this runs production scale infrastructure and is designed to handle production levels of traffic at a moment’s notice. As you might expect, most organisations would recoil at the idea of doubling an application’s infrastructure cost. You’ll normally find this strategy reserved for the most mission-critical of applications.

The first of our scenarios is an SMB SaaS application. It’s an application that allows people to upload photos of their expense receipts, add some information and share it with their manager for approval.
This application is currently deployed to a large shared virtual private server (VPS). In terms of resiliency, this is about as bad as it gets. There’s just one copy of the application deployed, meaning that if the server were to fail, manual intervention would be required to bring it back again, and customers of the SaaS application would be left waiting. It’s not a mission-critical application, so it’s not the end of the world, but it is less than ideal.
So, how could this be improved with AWS? The most comparable piece of infrastructure to a shared VPS would be an EC2 instance. Let’s run with that. Similarly to VPS’, an EC2 instance won’t give you resiliency on its own. An architecture with one large server rather than lots of small servers (horizontally scaled) needs to change to really improve this.
To accomplish what we want to do, we need to bring in EC2 Auto Scaling. EC2 Auto Scaling enables us to configure a minimum, maximum and desired count of EC2 instances to be launched. This can be done automatically with scaling policies (e.g. add an instance when average CPU utilisation breaches 75% for 5 mins), or it can be done manually if you can predict demand. Auto Scaling also supports replacing unhealthy instances when they have failed. These scaling groups can be configured to spread instances across multiple AZs, reducing exposure to single AZ failure and increasing resilience.
Now, there are some things to keep in mind with this.
Every time an instance is launched or replaced, it gets a new IP address. This means that DNS records end up out of date very quickly. You could do something clever with updating DNS zone records at various points of an EC2 instance lifecycle, but it’s messy and adds more things to go wrong. The best way to architect this is to use an Application Load Balancer and Target Groups. This will allow you to expose one endpoint for the application (the load balancers), and then the target groups keep track of the healthy instances to direct traffic to.
Something else to keep in mind is that your application servers themselves need to be stateless. This means that no data should be stored on the instance itself that you cannot afford to lose. If you have files generated by users, look to use Amazon S3. If you have a database then use Amazon RDS or Aurora. Decoupling stateful data from your application servers is key here.

Let’s imagine that we’ve got an enterprise scale financial application that handles the processing of trades for customers in the UK. The application is currently deployed on-premises to a single data centre in London. At a high level, the architecture is quite simple. It is a Java application with a PostgreSQL database for relational data. Generated documents are stored on a file server.
This application is mission-critical, and any extensive downtime risks fines from the regulator. As a result, it has been decided that the application will be migrated into AWS to ease the journey to increased resiliency.
Migrating into a single AWS region (i.e. London) could massively increase the resiliency of the application; however, there is an argument to be made that only being deployed to one region still leaves the risk of downtime higher than they are tolerant of. For this reason, when the application is migrated, it will be deployed to London as a primary region and Ireland as a secondary. But what disaster recovery should be used?
We know that downtime is allowed, but not for long. This rules out backup and restore or pilot light strategies. As to whether warm standby or active/active is required, that comes down to the cost of infrastructure vs. the potential cost of fines. For the purposes of this article, we’ll assume the fines are prohibitively large and active/active is required.
At its core, the architecture can look similar to that of the SMB SaaS application. A set of EC2 instances that are orchestrated by an Auto Scaling Group and fronted by an Application Load Balancer. The PostgreSQL database that is currently running on-premises can run on Amazon Aurora, and Amazon S3 can be used for scalable and durable storage.
AWS Regions across Europe. Source: AWS.
If it was only running in one region we could leave the architecture at that. Auto Scaling groups would handle launching instances across multiple AZs, S3 is durable across all AZs by default, and Aurora could be configured with instances in multiple AZs.
So, how do we make it multi-region and handle failovers? There are three key areas to make changes to.
First of all, thought needs to be given to how to make the transactional data stored in Amazon Aurora (PostgreSQL) accessible from the secondary region. To do this, we’ll use Aurora Global Databases. The way this works is that there are multiple clusters deployed across multiple regions, with the primary region the being only one that can perform write operations. In the event of a failure in the primary region, an API call can be made to initiate the global database failover process. This makes the read-only cluster in the secondary region the primary. This is a similar methodology to read replicas; however, Aurora Global Databases provision entirely separate clusters, allowing you to failover without having to wait for the provisioning of new infrastructure.
Next up, the same infrastructure that’s deployed in the primary region needs to be deployed into our secondary region. As we’re aiming for an active/active DR strategy, the capacity and sizing of the infrastructure should be the same. (If we were opting for warm standby then we’d have the same infrastructure but scaled down.) Once deployed, we can update the Route53 DNS record to point at the Application Load Balancer in both regions, and use Route53 Health Checks to determine when to return the value for the secondary region.
Last of all, we’ll set up bi-directional S3 cross-region replication between our primary region (London) and secondary region (Ireland). This will ensure that data is copied across in real time. The application deployed in the secondary region should be configured to write to the bucket in its own region. This, in conjunction with the bi-directional replication, will ensure that when the primary region returns to full health, the data will be automatically replicated back to the primary region, ready for switchover.
If something I’ve talked about resonates with a situation that you’re in, not to worry! There’s plenty of help available.
If you’re currently running applications on-premises and need greater resiliency, then it’s a migration into AWS with modernisation you’re looking for. The Migration Acceleration Program (MAP) is a great way to make your investment go further by utilising AWS funding specifically for these scenarios. It’s a straightforward way to get started on the journey to being more resilient to failure.
If you’re already in AWS and looking for an expert eye to help you to identify where your architecture could be improved to make it more resilient, a Well-Architected Framework Review sounds like the perfect exercise for you. These are cost-neutral and give you dedicated time with a Solutions Architect to talk through and review your infrastructure and then help get started with remediating their findings.
In both cases, please do drop us a message with any questions or inquiries and we’ll be in touch shortly.

Alex Kearns
Principal Solutions Architect, Ubertas Consulting

